Prezentujemy program konferencji: (Mikro)społeczności praktyk naukowego edytorstwa cyfrowego. Jak im służyć globalnie i lokalnie
13.00–14.00 – registration open and coffee break
14.00 – conference opening 1: Bartłomiej Szleszyński, conference manager, Director of the Department of Digital Editions and Monographs at the Institute of Literary Research of the Polish Academy of Sciences (IBL PAN)
14.05 – conference opening 2: Grzegorz Marzec, Director of the Institute of Literary Research of the Polish Academy of Sciences
14.10 – conference opening 3: Maciej Maryl, Director of the Digital Humanities Centre at the Institute of Literary Research of the Polish Academy of Sciences
The DraCor project, based on the concept of “Programmable Corpora” (Fischer et al. 2019), is an open platform and a growing network of resources for hosting, accessing, and analysing theatre plays. Presently including 19 corpora in 16 different languages, totaling about 3750 works, it provides scholars not only with a wealth of TEI-encoded digital texts, but also with applications and tools for research purposes – ranging from the computation of textual network metrics via extraction functions of the DraCor API to SPARQL queries and speech distribution statistics.
From its inception, the DraCor project has been open to small and large corpora of plays from any linguistic and cultural background, encouraging external scholars to prepare and submit their own texts. While the first, prototypical corpora, such as the German and the Russian ones, were built by the DraCor team, soon new collections were born out of community-driven efforts. Early examples included the Spanish, Hungarian, and Alsatian corpora – with the latter being notable for its low-resources approach (Ruiz Fabo et al. 2022). The most recent additions are the Ukrainian, Dutch, and Polish drama corpora. The Ukrainian corpus, built as an immediate response to the Russian aggression against Ukraine and its cultural heritage, has especially shown the strengths of a community-based corpus-building approach, as it has involved scholars specialising in Ukrainian studies and volunteers in the text collection and encoding phases. Thanks to the guidelines and markup automation tools developed by the DraCor team, the pipeline for onboarding new corpora has now been refined, allowing for efficient distributed work on multiple sets of texts.
Today, DraCor is a small but active community of digital literary scholars, research engineers, and other academic specialists. Together they produce DraCor-based research, maintain the DraCor platform, develop new tools, and onboard new corpora. Everyone who has an idea to add some plays to DraCor is welcome to join.
References:
coffee break
Recent decades have brought not only new theories in the field of digital humanities, further solutions and tools useful in digital editions, but also many new theories regarding drama as a literary form and drama as a component of a theatre performance. They are accompanied by interesting playwriting work in Poland, often going beyond the schematic framework of the dramatic form (although it should be said that theoretical phenomena develop thanks to the work they can analyse). These phenomena encourage theoretical reflection and the implementation of practical solutions that would meet the editorial needs, knowledge about drama and developing playwriting.
In my speech, I intend to be focused on the findings of contemporary theory of drama that may be useful in digital drama editions. I plan to indicate the needs that emerge from the analysis of the structure of contemporary dramas and the latest knowledge regarding dramatic form. It will also be important to reflect on the balance between creating new solutions and using existing tools that can be adapted to various needs. I am also going to discuss the dangers associated with the instability of new literary and theatre theories and try to point out mechanisms that can protect digital editors from being subjected to the particularity of theories and solutions, and will help develop their universality while maintaining sensitivity to the specific features of drama, especially contemporary drama, as a literary genre. It will be important to consider whether there is a need for separate editorial procedures in works on contemporary dramas and dramas from previous eras.
The material basis for the considerations will be paper editions of contemporary dramas from the series "Dramat Polski. Reaktywacja” [Polish Drama. Reaktywation], of which I was the editor, and above all, the experience gained from cooperation on the Cyfrowa Edycja Polskiego Dramatu Powojennego i Współczesnego [Digital Edition of Polish Post-War and Contemporary Drama] (on the tei.nplp.pl platform), enriched with new observations, comments and theoretical extensions based on my own research on Polish contemporary drama.
-----
16.00 – 16.10 – discussion
When looking at people in more technical roles in the digital humanities we can see a surprisingly high percentage of "humanists" by trade who turned "digital", into software developers, data engineers, technical editors and project managers. Crossing the technological divide has often been dictated by chance, or, more precisely, by
necessity: an archeologist turning into TeX guru to publish a lexicon series, a sociologist becoming database developer to be able to process research data, a historian building and running a complex network architecture to assure smooth and continuous service for the online edition of historical documents. Is it a paradox or, to the
contrary, a logical necessity that leading figures in DH largely have their background in humanities and little or no formal technical education?
Which leads us to the main question: what does it take to create technical components - tools or infrastructure - that serve a more general purpose and a larger community? What does it take for a community of practice to develop, flourish and grow?
In this talk we'll discuss a personal perspective on these subjects, supported by non-obvious professional paths of people instrumental to the creation and development of eXist-db, an XML database and application platform, the TEI Publisher, an open source framework for sustainable digital publications, and foundation of e-editiones, a
scholarly non-profit community dedicated to empower digital projects by promoting open standards and collaboration to sustain editions far into the future. All are examples of a positive feedback loop, where community needs and engagement shape the evolution of open source software and research workflows, leading to spontaneous self-organization, constantly influencing the community itself as well as the lives of developers and emerging leaders.
-----
16.40–16.50 – discussion
The TEI Panorama platform (TEI.NPLP.PL) and the specific editions that employ it build on and develop the traditions of Polish editing - in particular, the expertise accumulated over several decades at the IBL PAN. At the same time, they adopt the best practices and standards of digital humanities projects - they work with the TEI guidelines and solutions used in digital scholarly editions (DSE)around the world, try to adapt to the FAIR data principles and make the most of the opportunities created by the digital environment. The presentation will focus on how DSEs are created at the intersection of these two worlds, reconciling their requirements and thus creating a new quality.
-----
17.20–17.30 – discussion
lunch
registration open and coffee break
C21 Editions is a joint UK-Ireland digital humanities project funded by the Arts & Humanities Research Council and the Irish Research Council. The project aims to advance the state-of-the-art in digital scholarly editing by 1) establishing the protocols and best practices for creating scholarly editions of born-digital content such as social media; and 2) exploring machine-assisted approaches to the editing of digital scholarly editions.
In this talk I will report on the second strand of the C21 Editions Project. We explored the use of generative AI and machine learning, alongside open linked data, in order to create an online teaching edition of The Pardoner's Prologue & Tale from Geoffrey Chaucer's The Canterbury Tales. The edition features a diplomatic transcription, a modern translation, scholarly commentaries and annotations, an automatic text-to-speech narration of the Middle English text, and teaching activities that are aimed at training students to engage more critically with AI. The results of these approaches will be demonstrated and discussed, and their implications for the future of scholarly editing will be considered.
I will argue that Large Language Models (LLMs) and generative chatbots are now capable of undertaking the majority of scholarly editing tasks that we traditionally associate with critical thinking but which are routine, laborious and time-consuming. This requires the editor to assume a new role within the domain of scholarly editing: a more critical focus on editorial method; greater attention to the minority of editorial decisions that are more problematic; and co-editing with a machine (as co-pilot) through prompt engineering. Last but not least, the facility of AI to perform critical thinking tasks now leaves the editor free to focus on creative thinking (the production of new knowledge).
coffee break
Written in the Latin alphabet, early modern Ruthenian popular poetry belongs to the literary heritage of the Polish-Ruthenian cultural borderland. Little known so far due to its dispersion in Polish manuscripts of the silvae rerum type, it failed to enter the historical and literary circulation and remained on the fringes of the research on the popular works of the Polish-Lithuanian Commonwealth. Ruthenian poems were most popular in the 17th and 18th centuries, yet still their ‘national’ affiliation is sometimes difficult to establish, and the heterogeneous language and script make unambiguous classifications impossible.
The main purpose of this paper is to present the outcome of my research stay at the Institute of Slovenian Literature of the Research Centre of the Slovenian Academy of Sciences and Arts in Ljubljana in May of this year. During this period, I have successfully converted a traditional printed edition of Ruthenian poems (a corpus of 150 texts published as part of my doctoral dissertation) into a modern digital edition which has been edited in accordance with the standards set out in the Guidelines of the Text Encoding Initiative Consortium (TEI). Given the rarity of digital editorial projects related to early modern poetry, carried out by Polish scholarly institutions, it became necessary to draw upon the expertise of foreign specialists. Among projects run by the Institute of Slovenian Literature, one in particular – the ‘Slovenian Baroque Collection’ – appeared particularly suitable and comparable, especially in terms of its approach to heterogeneous Slavic texts written in Latin script. The TEI Publisher framework is employed for the online publication of digital editions of Slovenian literature. During the work on the digital edition of Ruthenian songs, extensive editing of text-critical structures was carried out and the validity of XML was constantly checked against a schema used for the editions of the ‘Slovenian Baroque Collection’. The TEI document of the Ruthenian songs was marked up and reorganized in accordance with the plan of the digital edition with the focus on primary sources rather than by thematic arrangement. The description of the primary sources, the transcription principles, the critical apparatus and the textual commentaries that were written in advance were also structured and integrated into the edition. The editorial work was completed by installing the eXist-db database and uploading the application containing the edition to the database. While this framework still requires further adaptation to the edition’s needs, the basic production cycle has been achieved and settled.
-----
12.15–12.25 – discussion
The goal of this paper is to reflect on the recent development of platforms dedicated to the publication of DSEs of scholastic Latin sources. The two leading initiatives relevant in this context are LombardPress, a virtual environment centred around an XML repository for scholastic commentaries, developed by Jeffrey Witt of Loyola University Maryland; and the Medieval Text Consortium, a collaborative series affiliated with Open Book Publishers aiming to create an open-access publishing alternative for traditional printed editions. Both projects have been many years in preparation and recently produced their first original publications: as of writing this proposal, the Consortium’s first publication is awaiting final corrections before its release, while LombardPress published an edition of Peter Gracilis’ commentary on Sentences in May 2023. These two publishing platforms stem from very different incentives, with LombardPress focusing on data science applications (primarily text-reuse recognition), and the Consortium aiming to facilitate access to printed (or printable) publications for the most part adhering to traditional publishing conventions. In this paper, I would like to argue that both projects should be seen as complementary and that they collectively provide a data-centred, distributed publishing environment that offers an opportunity to overcome some of the obstacles responsible for the still marginal position of digital publishing for the study of the scholastic tradition. Drawing on my recent experience of work for the Consortium as a LaTeX typesetter, I will discuss potential workflows enabling the transmission of material between these two projects. Given the low complexity of LombardPress TEI schema, the transformation from Consortium’s .tex files to appropriate TEI-XML requires relatively little semantic enrichment, offering the gain of providing a proper machine-readable resource. Meanwhile, even though documents functioning within the LombardPress repository already have a LaTeX-based PDF representation (a feature provided by LombardPress print module), I will argue that there remains a significant pragmatic gain in their introduction into the publishing framework of the Consortium, which through provision of affordable on-demand print, inclusion in conventional library catalogues, and high-quality open-access platform enhances edition’s findability. Thus, editions functioning within both publishing projects would constitute genuinely FAIR data; moreover, the distributed character of such a publishing environment would contribute to their sustainability. Notably, this approach promises to offer the long-sought convenient entry point for editors with little to no DH expertise, shifting focus from the development of integrated editorial environments towards institutional support of distributed expertise and workflow management.
Referenced publications:
Walter Segrave, Insolubles, Critical edition with English translation, ed. Barbara Bartocci, Stephen Read,
The Medieval Text Consortium (forthcoming)
Petrus Gracilis, Commentarius in libros Sententiarum Liber 1, Lectiones 1-20, ed. Jeffrey C. Witt, John T.
Slotemaker, LombardPress (Peer Reviewed by the Medieval Academy of America and the Digital Latin
Library), 2023
-----
12.55–13.05 – discussion
The dream of numerous editors of historical texts is the development of an intuitive and universal program for creating and visualizing digital editions. While such a tool for traditional paper editions has yet to be realized, there is no reasonable hope that this vision will soon become a reality. A significant obstacle is the multiplicity of editorial models necessitated by the diverse nature of the texts being published. This paper examines this issue through three ongoing projects: the Monumenta Vaticana res gestas Polonicas illustrantia edition, Szymon of Lipnica's Liber miraculorum, and the sermons of Henryk Bitterfeld, each exemplifying different types of editions and their respective infrastructural requirements.
Monumenta Vaticana project involves the edition of extensive diplomatic sources, ultimately encompassing over a thousand documents of papal origin. These documents contain a wealth of prosopographical and geographical data, as well as information on secular and ecclesiastical institutions and offices. Their digital publication necessitates both a full-text edition in the TEI standard and an associated database in RDF format, which accommodates both explicit and implicit data within the texts. Conversely, at the other end of the spectrum are sermons, typically literary works. Their edition does not necessitate the creation of a separate database, with the editorial process confined to XML files in the TEI standard, incorporating critical and source apparatus. The primary challenge here is to create a visualization that allows for the comparison of different manuscript versions of the text. Positioned between the Vatican sources and the sermons is Szymon of Lipnica's Liber miraculorum. This text, while a literary work, also serves as a historical source containing prosopographical, geographical data, and information on votive offerings, religious practices, and types of diseases. Consequently, it necessitates a full-text edition with a critical apparatus, as well as a searchable database. Given that most characters in the text are otherwise unknown and cannot be unambiguously identified, it is impractical to create a database akin to that used for Vatican sources. Instead, lists of places, persons, objects (such as votive offerings), and events are annotated in the TEI standard as metadata.
Each of these editions requires distinct search criteria and mechanisms, as well as different visualizations, necessitating varied IT infrastructures. Therefore, even an editor proficient in digital humanities requires the assistance of an IT specialist from the outset. Each digital edition is a collaborative effort requiring domain-specific knowledge and the adaptation of existing tools to meet specific project needs. These challenges can discourage many, especially those lacking institutional support, from undertaking such efforts. This is further compounded by current evaluation criteria for scientific activity, citation practices, and the sustainability of such work.
Is there a way to change this state of affairs? What requirements must IT infrastructure meet to be useful for different types of editing? Is it currently possible to create such infrastructure? This paper aims to inspire the search for answers to these questions by highlighting the specific needs and challenges facing editors of various types of texts.
BIbliography
-----
13.35–13.45 – discussion
lunch
We present the HISe (Henrik Ibsen Skrifter) DSE of Henrik Ibsen’s work at the CIS (Centre for Ibsen Studies) at the University in Oslo. We provide a comparative study of its current implementation with alternative implementations. The current DSE is fully based on XML standards. Corpus is encoded in TEI and stored in an XML database that is searched through a set of xQuery scripts. We use Cocoon (relying on XML configuration and XML transformations) as a web service and for web framework we use a set of additional XML documents for static content and XSLT transformations for transforming both the static content and corpus. Having such a solution, we are facing critical choices in our further development that comes to the following challenges: (1) the solution itself is over 10 years old and originates from TEI-publishing projects that evolved into an online solution and as such it calls for more advances features while also aging (considering its digital life realm). (2) Interest in XML and
its dominance has continuously deteriorated over the last 2 decades making it both an un attractive technology abandoned both from the modern development trends but also by XML standard maintainers themselves (just a single example of never finished xQuery standard extension to support updating XML documents). (3) Considering Henrik Ibsen's birth anniversary in 2028 we are both and expected to present new features of the DSE which increases our dilemma when it comes to further investment in our XML solution especially considering it is not multi-language friendly (currently it is primarily Norwegian except the theater performances which are primarily English). (4) Most advanced NLP, ML, and AI tools work more fluently with simpler and lighter document encodings. Finally, (5) an institution responsible for maintaining the HISe DSE is both unfamiliar with TEI and its accompanying tools and unwilling to invest in and maintain a heavy XML-based infrastructure. We explore alternative solutions; of which the 3rd we demonstrate in more detail and the last in a separate presentation. First, (1) we consider 3rd party TEI-native solutions that support standard web frameworks for UX rather than XML-based. (2) We evaluate solutions with dual corpus utilizing both XML and its derivatives together with SQL database. (3) We currently migrate multiple HISe components from XML solutions to alternative ones while trying to keep the whole platform unaffected by the end user. (4) We explore advanced semantic and ontological solutions relying on OWL, RDF, and JSON-LD and a more FAIR- friendly platform. (5) Finally, partnering with LitTerra Foundation in a few pilot projects, we evaluate a solution where the TEI corpus coexists as a source-of-truth with its pure derivatives used for NLP/AI analyses and UX rendering. Juxtaposing the 5 challenges and 5 often orthogonal alternatives we believe our work brings an exciting arena for discussion on the DSE technologies and at least a few valuable directions and takeaways of our journey.
-----
15.30–15.40 – discussion
How to balance between a TEI/XML corpus, which provides comprehension and expressiveness to human actors in the DSE maintenance process, and an externally
annotated pure textual corpus that offers greater simplicity of textual processing and visualizing?
Partnering with Centre for Ibsen Studies and the Institute of World Literature SAS over a few projects, LitTerra Foundation evaluates the usage of the LitTerra platform for two scenarios: (1) the TEI corpus (in this case, Henrik Ibsen's multilingual corpus) coexists as a source of truth with its pure text derivatives and (2) the corpus is a pure text or lightly annotated (in this case Vladimir Nabokov's multilingual work).
This triggers even the larger question: how to create a low-maintenance but extensible and sustainable DSE platform that will handle such foundational struggles of socio-technical evolution?
LitTerra takes a novel approach to implementing DSE with the following features: (f1) workflows - LitTerra features are implemented as workflows, letting users to implement their own and to update pre-existing workflows using a visual workflow editor, (f2) annotations - LitTerra supports rich corpora augmentation through annotation sets, some preset (like POS, NER, critical editing) and others custom (like etymology, manual annotations), (f3) NUI (Natural [language] User Interface) - there is a foundational NUI support augmented with AI models that users can use to interact with DSEs, (f4) layouts - LitTerra supports advanced multi-row/column and matrix layouts, (f5) augmented reading and writing - through generalization and agnostic approach, LitTerra augments the corpus with multi-media, distant-reading and close-reading (meta-)data, (f6) collaboration - LitTerra supports collaboration on corpus, annotations, workflows, (f7) extensibility - by externalizing functionality into workflows and generalizing corpus augmentation with annotations, LitTerra is highly extensible and customizable, (f8) provenance - it enables tracing the origin and production mechanism of any corpus entity, (f9) versioning - LitTerra versions all of its entities.
LitTerra exemplifies the principle of extensibility (f7) (here and below, each number refers to the above-mentioned features) in handling TEI corpora. There are dedicated workflows (f1) for importing TEI corpus and generating annotations (f2) from the imported corpus that will augment (f5) the pure textual derivatives through an advanced layout (f3) and let users interact with it in a natural way (f4). Pure derivatives of the original TEI corpus allow for simple workflows (f1) integration of all the tools, for corpus augmentation (f2), and for non-XML-dependent UX rendering.
All the benefits do not prevent later interventions on the original TEI corpus. The TEI corpus remains the main source-of-truth and first-place DSE citizen. Through manual annotations (f2) and collaboration (f6), DSE users can spot any mistake in the original TEI corpus and update the corpus or workflows. Thanks to support for versioning (f9) and the provenance (f8) of corpora and workflows, LitTerra DSE is capable of " on-the-fly " regeneration of all the necessary meta-data in a reproducible manner.
Finally, we demonstrate LitTerra's extensibility and sustainability through (1) the integration of additional tools in the search mechanism to support fuzzy, cross-synonyms, and cross-lingual search, (2) the addition of etymology tools with its dedicated etymological annotation set, (3) support of generative AI in "jamming" literary texts.
-----
16.10–16.20 – discussion
The talk will present the PoeTree project—a standardized collection of poetic corpora comprising over 330,000 poems in ten languages (Czech, English, French, German, Hungarian, Italian, Portuguese, Russian, Slovenian and Spanish).
With advances in computational literary studies, the demand for open multilingual datasets has been increasing, be it for the purpose of comparative literary research [1, 2], as benchmark for new stylometric methods [3, 4], or as training data for multi-lingual models that aim to enhance literary text annotation and processing pipelines [5, 6, 7]. Several relevant resources are already available for prose fiction, including the European Literary Text Collection or ELTeC [8] and benchmark corpora built by the Computational Stylistics Group (2023). In addition to these, the expansive DraCor project [9] contains dramatic texts across numerous languages and periods. This leaves poetry, the last of the three main literary genres, without a dedicated resource, a situation that
hinders research in computational poetics and comparative poetry studies.
PoeTree aims to fill this gap. Data stemming from various projects has been standardized into a unified JSON structure. All corpora have been deduplicated, morphologically tagged, parsed for syntactic dependencies with UDpipe, and authors linked to their respective VIAF and wikidata entity ids. Entire dataset is available at Zenodo (https://doi.org/10.5281/zenodo.10907309), or can be accessed via its REST API (https://versologie.cz/poetree/api_doc), Python library (https://pypi.org/project/poetree/) or R library (https://github.com/perechen/poetRee).
We will also present some work in progress, namely the current stage of fixed forms (sonnet, sestina, etc.) recognition and named entity linking to a common knowledge base (wikidata).
References
[1] Artjoms Šeļa, Petr Plecháč, and Alie Lassche. “Semantics of European poetry is shaped by conservative forces: The relationship between poetic meter and meaning in accentual-syllabic verse”. In: PLOS One 17.4 (2022). doi: 10.1371/journal.pone.0266556.
[2] Grant Storey and David Mimno. “Like Two Pis in a Pod: Author Similarity Across Time in the Ancient Greek Corpus”. In: Journal of Cultural Analytics 5.2 (July 8, 2020). doi: 10.22148 /001c.13680.
[3] Petr Plecháč. Versification and Authorship Attribution. Prague: Karolinum Press, ICL, 2021. doi: 10.14712/9788024648903. url: https://versologie.cz/versification-authorship/.
[4] Keli Du, Julia Dudar, and Christof Schöch. “Evaluation of Measures of Distinctiveness. Classification of Literary Texts on the Basis of Distinctive Words”. In: Journal of Computational Literary Studies 1.1 (2022). doi: 10.48694/jcls.102.
[5] David Bamman. BookNLP. GitHub, 2021. url: https://github.com/booknlp/booknlp.
[6] Joanna Byszuk, Michal Woźniak, Mike Kestemont, Albert Leśniak, Wojciech Lukasik, Artjoms Šeļa, and Maciej Eder. “Detecting Direct Speech in Multilingual Collection of 19th-century Novels”. In: Proceedings of LT4HALA 2020 - 1st Workshop on Language Technologies for Historical and Ancient Languages. ELRA, 2020, pp. 100–104. url: http://www.lrec-conf.org/proceedings/lrec2020/workshops/LT4HALA/pdf/2020.lt4hala-1.15.pdf.
[7] Javier de la Rosa, Álvaro Pérez Pozo, Salvador Ros, and Elena González-Blanco. ALBERTI, a Multilingual Domain Specific Language Model for Poetry Analysis. 2023. arXiv: 2307.01387 [cs.CL].
[8] Carolin Odebrecht, Lou Burnard, and Christof Schöch. European Literary Text Collection (ELTeC): April 2021 release with 14 collections of at least 50 novels. Version v1.1.0. Zenodo, Apr. 2021. doi: 10.5281/zenodo.4662444.
[9] Frank Fischer, Ingo B¨orner, Mathias Göbel, Angelika Hechtl, Christopher Kittel, Carsten Milling, and Peer Trilcke. Programmable Corpora: Introducing DraCor, an Infrastructure for the Research on European Drama. Zenodo, Nov. 2020. doi: 10.5281/zenodo.428400
The presentation introduces the "Corpus of the Four Bards" project, which aims to create a comprehensive corpus of works by the most significant Polish Romantic writers: Adam Mickiewicz, Juliusz Słowacki, Zygmunt Krasiński, and Cyprian Norwid. Their literary record will be transformed into a multi-layered repository of texts consisting of four scholarly curated sub-corpora that will include not only literary texts but also all other relevant written documents (notes, marginalia, inscriptions on drawings, etc.).
The influence of these poets’ work on both high and popular Polish culture, along with numerous references to their creations, is firmly embedded in the language and arts and constitutes the core of the paradigm of Polish identity. The study of their works, interconnections, and various cultural references should be based on access to a professional database. Currently, such a database does not exist – the project aims to fill this gap.
The design of the Corpus of the Four Bards aims to integrate the anticipated needs of the end user such as searching for all uses of a given word in a selected idiolect, studying the distribution of a given word or group of words, tracing the chronology of specific words, tracking the variability of the idiolect over time or making hypotheses about the development of Polish language in general. The objectives of the emerging corpus are: 1. to provide electronic, scholarly curated versions of the texts (not just literary works!) of all four authors; 2. to apply tools that, through metadata and annotations generated by the project, will enable comprehensive research across the entire corpus or its components (individual authors, genres, date ranges).
During the presentation, the workflow for processing the materials that make up the corpus will be outlined, including complex issues related to scholarly curation: text standardization (modernization, proofreading), as well as the annotation system that allows for efficient navigation within the corpus and retrieval of data of interest to the researcher. A specialized metadata system, designed specifically for the corpus, will also be discussed.
To date, a corpus of poetic texts and a pilot corpus of texts from other genres have been created. Based on this foundation, preliminary research can already be conducted, demonstrating the value of the prospective corpus. These studies were carried out using research infrastructure provided by CLARIN-PL and are based on Natural Language Processing methods.
An important element of the presentation is highlighting the differences between a strictly editorial approach and the corpus curation concept. At various stages of corpus preparation, it is necessary to make fundamental editorial decisions; however, the manner of presentation and use of the obtained material, as well as the style of the adopted annotations, significantly differs from traditional editing. At the same time, the curated corpora may be utilized in the preparation of new editions of the presented texts.
-----
17.30–17.40 – discussion
registration open and coffee break
The main goal of the Open Research Data (ORD) project Proto4DigEd funded by swissuniversities for a duration of 18 months (07.2023−12.2024) is to test and further develop prototypical workflows for digital scientific editions (DSE). As a result, we are developing a model edition and writing an extensive handbook that aims to help different use cases and communities in the conception phase of their projects.
Proto4DigEd answers to a growing need for standardisation concerning digital edition projects (Pierazzo 2019: 2014). For this aim, the project links its handbook to its model edition, using a small subset of the huge correspondence of Gaston Paris (1839-1903), one of the most influent European philologists of the 19th century.
The Proto4DigEd handbook is concerned with all stages of the data life cycle from the conception phase until the archiving of the data in a repository. The project is not intended to document new technical solutions, but focuses on a combination of easily available, long-time proofed and thus sustainable tools and on seamless transitions between them.
It focuses mainly on three solutions for the main phases of a DSE project (transcribing, editing, publishing and archiving). 1. For the automated transcription of manuscripts (HTR) the tool Transkribus offers general text recognition models as well as the training of specific models and is at present the de-facto standard solution in DSE in the community. 2. TEI Publisher is a publishing toolbox developed in Switzerland and Germany that is supported by a growing community and allows standardised markup of texts in TEI-XML and their online publication. 3. The DaSCH Service Platform (DSP) allows long-term archiving and long-term visualisation of edition data. The handbook informs readers about different ways in which to use these or similar solutions, that fit the technical, personal and institutional framework of their projects.
We are organising workshops, in which we discuss and compare workflows of different projects and ask them for their best practices. The focus is on the question of how projects can learn from each other, despite their differences. Sharing experiences when deciding on certain workflows and the use of tools is proving to be particularly promising. It is particularly important to consciously reflect on which functionalities are necessary and which are 'just' nice to have.
Our community driven handbook is based on MkDocs and will be made available on the GitLab instance of the University of Zurich from autumn 2024. The Center Digital Editions & Edition Analytics, ZDE UZH, helps in sharing the workflow and offers discussion and training to any interested project; for this we envision to put the workflow – beside other modes of communication – on the SSH Open Marketplace.
References
-----
11.00–11.10 – discussion
Hans Christian Andersen Centre at the University of Southern Denmark in Odense has a sizeable portfolio of more or less scholarly digital editions (DSEs) including Andersen’s printed works (close to 1000) and correspondence (more than 13.000 letters) along with English translations of his 157 canonical Fairy Tales and Stories.
Each edition project had its own editorial practices and have used three distinct frameworks. I therefore focus on the fourth DSE, an edition of manuscripts begun in 2017 and set to conclude by 2032 (with full funding until 2026). The manuscript edition is used to illustrate general insights:
The national overarching digital infrastructures in Nordic countries do not (yet) cater for the needs of DSEs. However, for more than 25 years, Nordic scholars have established a forum on how best to transfer the diverse scholarly traditions to encoding and the ever-evolving possibilities and challenges inherent to digital media.
Similar transnational organization efforts are needed in order for an advanced community-based framework to achieve the institutional support that ensures long-term sustainability. Funding by EU-programs and/or commitment from a national scientific academies or similarly stable institutions are viable alternatives to the national infrastructures.
Main references
Local
National
-----
11.40 – 11.50 – discussion
Scholarly editions prepared and published as books reflect a variety of methodological approaches and serve the needs of different scholarly communities. They largely benefit from a well-established publishing process that includes academic institutions, publishing houses with their armies of editors, proofreaders, designers and DTP departments, printers with their machines, and complex distribution networks. In discussions of the infrastructure for digital scholarly editing, this process is addressed, if at all, with little or no acknowledgement. Nonetheless, it is general and flexible enough to effectively meet the different needs of various authors and is sufficiently familiar not to be a major obstacle to scholarly work. In this light, building an infrastructure that effectively caters for the needs of digital scholarly editions takes on appropriate proportions. It is about creating a similarly complex digital publishing process: predictable, standardised and efficient, flexible enough and with some room for innovation. Not to mention the issue of academic assessment.
In my paper, I will discuss an attempt to build the Jagiellonian Digital Platform, a digital environment designed to serve the needs of academic editors at Jagiellonian University (part of the Digital Humanities Lab flagship project). Starting from the bottom, we have identified these needs, incorporated them into our project, and are now working on appropriate solutions to underpin the future infrastructure. Drawing on the experiences of scholarly editing practitioners, I will present the point of view of scholarly editors (mainly historians and literary scholars) who want to create editions initiated as digital projects, rather than print editions adapted to digital media. The issues of editing methods, data models, workflows, tools (with the absolute necessity of a WYSIWYG xml editor), skills etc. will be presented, which will be transformed into the small-scale process described above.
-----
12.20 – 12.30 – discussion
lunch
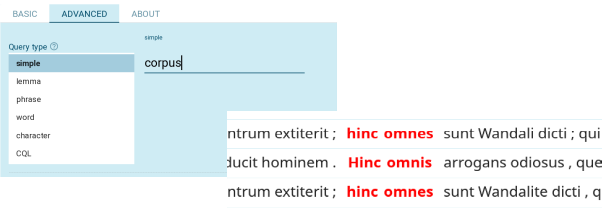
The primary objective of the Electronic Corpus of Polish Medieval Latin eFontes is to equip scholars with a robust tool for efficiently studying the diverse uses of Latin in the Polish Kingdom during the Middle Ages. Recently expanded, the corpus now contains approximately 15 million tokens, currently undergoing annotation with a part-of-speech and named entity tagger developed within the project. The central access point to the corpus is an instance of the NoSketchEngine (Figure 1) corpus query engine , enabling users to craft complex queries to explore vocabulary, grammar, and syntax.[1]
However, studying medieval texts is inherently multidisciplinary, requiring engagement with both linguistic and cultural data, as well as historical expertise. Medieval studies demand a dynamic approach to texts, as scholars are interested not only in the sequence of words but also in the material form of manuscripts, their evolving functions, and the editorial choices made over time. Hence, in addition to corpus linguistic tools, the eFontes project offers two more access points: the Editiones platform and a Semantic Web endpoint focused on bibliographic data, project ontology, and controlled vocabularies (Figure 2).
The Editiones platform (Figure 3),[2] built atop the TEI Publisher, serves two main purposes. First, it provides scholars and students with access to facsimiles of both modern and pre-modern text editions used to compile corpus data. Most of these editions stem from critical works published between the 19th and 21st centuries. Additionally, some texts have been acquired using custom recognition models trained on ground truth datasets prepared by the eFontes transcription teams. These include late 15th and early 16th-century philosophical texts preserved only in incunabula and early printed books, as well as a selection of late 15th-century charters preserved in manuscripts. The second goal of the Editiones platform is to provide early access to a wide array of automatically retrieved post-medieval texts that, although not meticulously proofread, can still be valuable for research.
The platform is closely linked to the OntoFontes website,[3] which aggregates and disseminates research data produced by the project as Linked Open Data . This includes rich metadata assigned to texts and editions which enables corpus linguists to effectively utilize analytical tools, refine their queries, and compile custom sub-corpora for comparative studies and keyword extraction. Given the diversity of medieval studies, different research communities may not always agree on the taxonomy of medieval genres or the labeling of so-called loca scribendi . Therefore, it is essential to map the project's classification system to external schemes relevant to the domain (Figure 4). Metadata management is facilitated by the project's ontology and a set of controlled vocabularies. Lastly, the eFontes project has launched several initiatives to engage with the research community, discussing corpus design and teaching prospective users the foundations of digital humanities and digital editing through workshops and seminars.
[1] Available at https://corpus.scriptores.pl.
[2] The demo installation is available at https://editiones.scriptores.pl.
[3] Available at https://onto.scriptores.pl from the September 2024.
References
-----
14.00-14.10 – discussion
H2IOSC is an Italian infrastructural project to create advanced services for researchers of the Humanities, Heritage and Social Sciences disciplines.
Funded through the Next Generation EU program, this 41.7 million euro initiative is producing a rich ecosystem of services: amongst them, there is the Digital Philology Hub (DPH) which aims to offer a complete solution for any philologist who wishes to create and publish on the web a Digital Scholarly Edition based on their studies of ancient manuscripts.
The DPH is composed of two components, the Back-Office and the Front-End. The former offers a complete workflow inspired by the best philological research practices, in which a researcher can create a project that can be either personal or collaborative, with multiple scholars invited to work on it and exchange ideas.
For this purpose, the DPH integrates access to different philological repositories and digital archives. This endeavour simplifies the research workflow, allowing users to locate and reuse relevant philological materials from a single interface. By searching through multiple attributes and faceted filters, manuscripts can be easily found and added to the project. If available, the URLs of the IIIF manifests, which offer an interactive vision of the scanned manuscript pages, can be imported as well.
Once manuscript metadata are imported into the project, philologists can work on their textual transcriptions. The DPH offers multiple options, from importing already existing XML/TEI transcriptions to creating new ones from scratch, through an easy-to-use on-line editor that can allow text editing either through a visual/WYSIWYG interface or an advanced XML editor.
When the manuscript texts are available, the collation work can start. Texts can be viewed side by side, to ease the detection of variants. Automatic collation and lemmatization services will be also integrated, to guide scholars in the creation of the critical apparatus.
Finally the construction of the critical edition can start: through a visual and intuitive interface, researchers can link a portion of text to the annotations of the apparatus and the relevant comments. Further research tools, including the creation of the text glossary and an interactive interface to construct the "Stemma Codicum", will also be integrated in the course of the project.
When ready, the researcher can publish the Scholarly Edition on the DPH Front-End, by also storing all the raw files created in the process in a long-term preservation archive. The Front-End allows users to access the produced study and offers several functionalities, including XML/TEI visual presentation, IIIF image visualisation and advanced textual and metadata search. It is designed not only as a tool for specialists, but also to successfully disseminate the results of the research to a wider audience.
The development of the DPH is an ongoing collaborative work in which research teams from OVI/CNR and designers and developers of two Italian SMEs, Net7 and META, have joined forces to ease the transition to a “digital first” approach for Humanities research in Italy, and possibly in Europe in a near future as well.
-----
14.40–14.50 – discussion
Correspondence is one of the most frequent types of digital scholarly edition (DSE), according to the Patrick Sahle’s DSE catalog of (140 of 908 editions in total) [1]. Also, according to the TEI Special Interest Group Correspondence [2], it enriches historical and literary research, while manifesting a diversity of forms like episteles, telegrams, postcards etc.This leads to a provocative hypothesis: if that literary and formal diversity of correspondence translates into a heterogeneity of specific needs of its editors and users, should we speak of many micro-communities defined by these heterogeneous needs, instead of grouping them under the general label “correspondence”?
In this presentation we will discuss in detail/with considerable granularity i two cases of correspondence communities, namely the creators and users of two digital scholarly editions of pos-twar (1940s to 1960s) literary correspondence published on TEI Panorama: the exiled Skamander poetry group, and between writers Maria Dąbrowska and Anna Kowalska, who, in contrast, remained in the Polish People's Republic after the war. We will especially investigate the data in the editorial commentary in regard to persons, works and corporate entities, collected in a single authority file on TEI Panorama as a form of enhanced index of entities. Each of them might have a ‘static’ description, relations with other entities within this index, as well as links to Wikidata and European Literary Bibliography. Authorship (in case of persons) and in-text mentions (in case of all entities) are automatically indexed, and accompanied by usage metrics of a particular entity - exact uses in each of edition.
We will compare those data and try to find out why they differ in those two editions of letter exchange, how this is connected to the specific needs of creators and users and, given this specificity, are we still talking about the same correspondence community.
Finally, we will discuss ways of increasing usage of already existing data in the future scholarly editions on TEI Panorama, along with answering specific requests from Polish editors.
[2] https://tei-c.org/activities/sig/correspondence/
-----
14.50–15.30 – discussion
Closing of the conference: Bartłomiej Szleszyński, conference manager, Director of the Department of Digital Editions and Monographs at the Institute of Literary Research of the Polish Academy of Sciences (IBL PAN)